« CLIP » : différence entre les versions
Aucun résumé des modifications |
Aucun résumé des modifications |
||
| (7 versions intermédiaires par le même utilisateur non affichées) | |||
| Ligne 11 : | Ligne 11 : | ||
" CLIP is an open source, multi-modal, zero-shot model. Given an image and text descriptions, the model can predict the most relevant text description for that image, without optimizing for a particular task." | " CLIP is an open source, multi-modal, zero-shot model. Given an image and text descriptions, the model can predict the most relevant text description for that image, without optimizing for a particular task." | ||
https://wiki.backprop.fr/images/1*ag6qUFmmXAr4E410Ll-eSQ.jpeg | |||
Voir le notebook à ce sujet : CLIP | |||
https://colab.research.google.com/drive/1kr0xnHQZ7G-cvlFgl2DECmLUbpgvswcy?usp=sharing | |||
Version actuelle datée du 12 janvier 2023 à 16:21
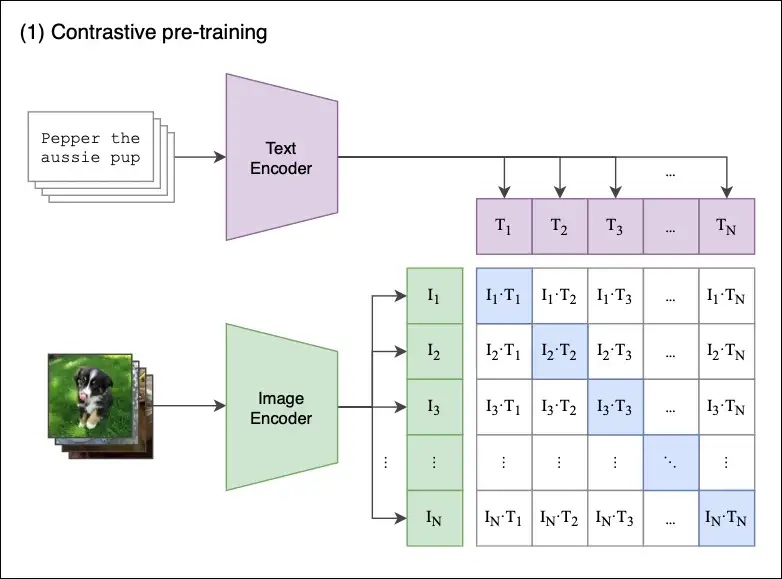
CLIP pour (Contrastive Language–Image Pre-training) a été introduit par OpenAi en 2021.
L'objectif est de fournir un text (caption) pour une nouvelle image présentée lors de la phase d'inférence.
Cette méthode CLIP permet de contourner certains problèmes de l'apprentissage supervisé, par exemple, ceux liés aux coûts des Datasets (voir ImageNet), à leur limitation de prédiction à l'ensemble des catégories entrainées, et à leur faible performance (parfois).
L'apprentissage décrit par OpenAi s'est fait avec 256 GPU durant 2 semaines. Il semble que 400M de paires(caption/image) aient été utilisées pour l'apprentissage.
" CLIP is an open source, multi-modal, zero-shot model. Given an image and text descriptions, the model can predict the most relevant text description for that image, without optimizing for a particular task."
Voir le notebook à ce sujet : CLIP https://colab.research.google.com/drive/1kr0xnHQZ7G-cvlFgl2DECmLUbpgvswcy?usp=sharing